Chapter 3: SQL¶
一、简介¶
- SQL 的组成部分
- 数据定义语言 Data Definition Language
CREATE / ALTER / DROP tableCREATE / DROP indexCREATE / DROP viewCREATE / DROP trigger
- 数据操作语言 Data Manipulation Language
SELECT … FROM …INSERTDELETEUPDATE
- 数据控制语言 Data Control Language
GRANTREVOKE
- 数据定义语言 Data Definition Language
- 注意细节
- SQL 的 name 对大小写不敏感
- SQL 的 name 不允许出现
-连字符
二、数据定义语言¶
1. 域的类别 Domain Types¶
char(n):固定长度为 n 的字符串varchar(n):可变长度的字符串,最大长度为 nint:整数,支持范围取决于机器smallint:短整数,支持范围取决于机器numeric(p,d):十进制定点数,共 p 位,其中小数点右侧 d 位real、double precision:浮点数和双精度浮点数,精度取决于机器float(n):浮点数,至少 n 位date:日期,格式YYYY-MM-DDTime:时间,格式HH:MM:SS或HH:MM:SS.MStimestamp:时间戳,格式YYYY-MM-DD HH:MM:SS.MS
2. 创建、删除和更改表¶
-
创建表
- 指定表名
- 指定属性的名、类型和完整性约束(integrity constraint)
- 指定主键:
primary key(key-name) - 指定检查条件:
check(expression)
示例:
CREATE TABLE branch ( branch_name char(20) not null, branch_city char(30), assets integer, primary key (branch_name), check (assets >= 0) );- 删除表
- 格式:
DROP TABLE table-name - 修改表
- 新增属性:
ALTER TABLE table-name **ADD (attribute-name-1 type-1, … , *attribute-name-n* type-n);对于表内已有的元组,新增属性对应的值为 NULL - 删除属性:
ALTER TABLE table-name DROP attribute-name - 修改属性类型:
ALTER TABLE table-name MODIFY (attribute-name-1 new-type-1, ... , attribute-name-n new-type-n)
3. 创建和删除索引¶
- INDEX 和 UNIQUE INDEX
- INDEX:允许被索引的数据列包含重复的值
- UNIQUE INDEX:不允许被索引的数据列包含重复的值
- 创建索引
- 格式:
CREATE INDEX index-name ON table-name(attribute-name-1, ... ,attribute-name-n) - 格式:
CREATE UNIQUE INDEX index-name ON table-name(attribute-name-1, ... ,attribute-name-n)
- 格式:
- 删除索引
- 格式:
DROP INDEX index-name
- 格式:
4. 创建、删除和使用视图¶
-
创建视图
-
格式:
-
-
删除视图
- 格式:
DROP VIEW view-name
- 格式:
示例:
视图的创建
视图的使用

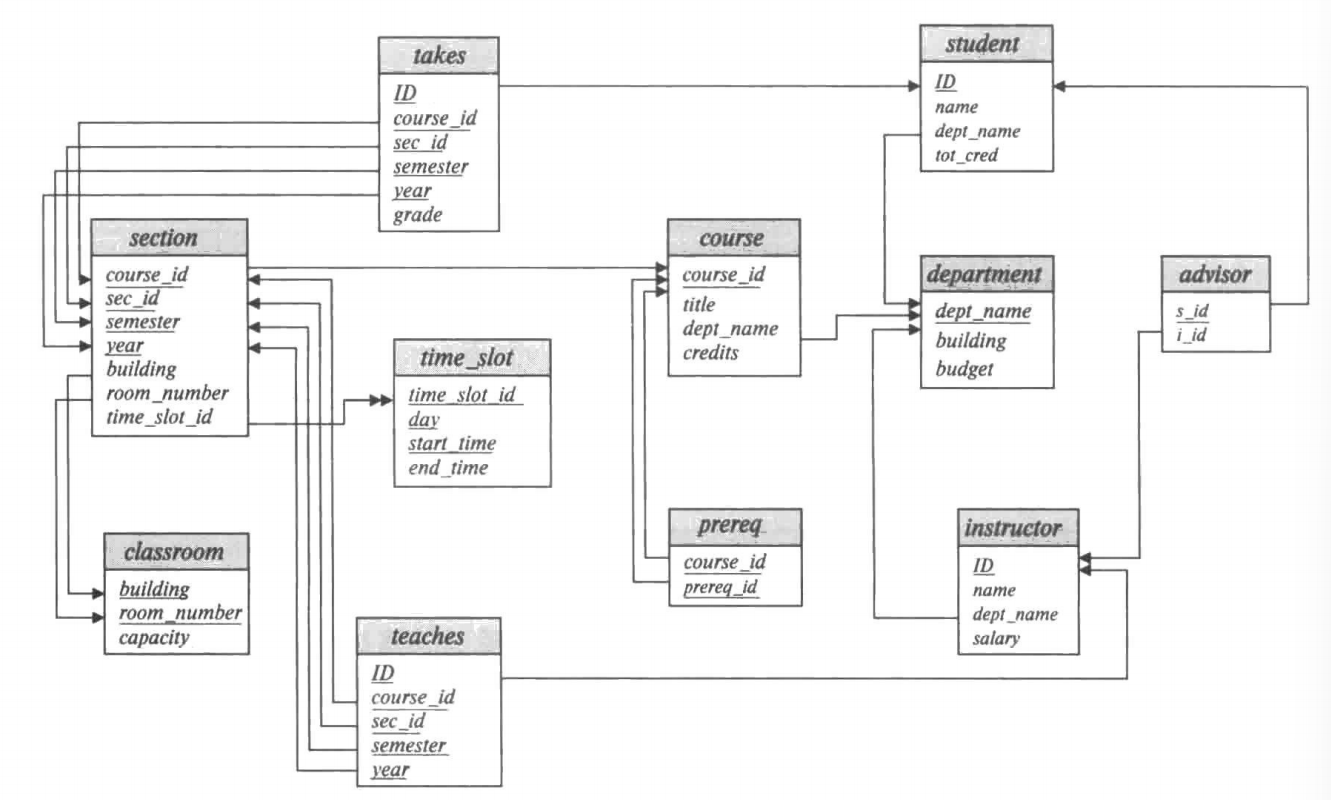
三、基本查询语句¶
1. SELECT … FROM … WHERE …¶
-
SELECT谓词- 支持使用通配符查询所有属性:
SELECT * FROM table-name - 支持简单的数字运算(+、-、*、/):
SELECT amount * 100 FROM table-name - 解决重复
- 在查询中,默认支持重复元组的输出
- 若要对输出进行去重,需加关键词
distinct - 若不对输出进行去重,可加关键词
all;但这是默认的关键词,因此不必加
示例:
Find the names of all branches in the loan relations, and remove duplicates
解:
SELECT distinct branch-name FROM loanWHERE谓词- 每个条件表达式之间使用
AND、OR连接 - 可用
NOT进行取反 - 可用
BETWEEN … AND …表示范围
示例:

FROM谓词- FROM 谓词后接的表名若超过一个,则为这些表作笛卡尔乘积
- FROM 谓词后接的表名若超过一个,且不同的表中有同名属性,则在访问这些属性时,需指明表名
示例:

- 支持使用通配符查询所有属性:
2. Rename¶
-
对列重命名
- 在
SELECT谓词中进行,目的是在输出显示时更加直观 - 实现方式
old-name AS new-namenew-name = old-name(SQL Server)
示例:
SELECT borrower.loan_number as loan_id, amount FROM borrower, loan WHERE borrower.loan_number = loan.loan_number- 对表(元组变量)重命名
- 在
FROM谓词中进行,目的是简化表达式或在同一张表内进行比较操作时解决名称冲突
示例:Find the names of all branches that have greater assets than some branch located in city Brooklyn.
- 在
3. 字符串匹配¶
- 通配符
%匹配任何子字符串_匹配任何单个字符
-
匹配方法
- 关键词:
LIKE - 支持逃逸字符
示例:

- SQL 支持的字符串操作
||用于连接字符串upper()和lower()用于转化大小写- 获取字符串长度,提取子字符串 …
- 关键词:
4. 为输出排序¶
- 关键词:
ORDER BY - 递增
asc,递减desc,其中递增为默认值 -
可以指定多个属性进行排序,优先级从第一个属性向后依次递减
示例:
5. 集合操作¶
- 关键词:
UNION(并)、INTERSECT(交)、EXCEPT(差) - 若使用上述关键词,则会自动消去重复项
-
若需保留重复项,应使用关键词:
UNION ALL、INTERSECT ALL、EXCEPT ALL
示例:Find all customers who have a loan or an account or both.
6. 使用聚合函数¶
- 聚合函数的种类:avg、min、max、sum、count(计数)
-
格式 1:直接使用
示例:Find the average account balance at the Perryridge branch.

- 格式 2:分组聚类
- 关键词:
GROUP BY - 被作为分组依据的属性必须出现在
SELECT语句的查询对象中
示例:Find the average account balance for each branch.

- 解决重复
- 聚合函数默认不解决重复,若需要解决重复,需使用关键词
DISTINCT - 在
count等函数中,需要尤为关注这一点
示例:

- 解决
NULL - 若某一元组使用聚合函数的属性为
NULL,则聚合函数会忽略这一元组,但count函数除外 HAVING谓词- 由于执行顺序的差异,
WHERE谓词内不可以使用聚合函数。若希望使用聚合函数对输出值进行筛选,则需要使用HAVING谓词
示例:Find the names of all branches located in city Brooklyn where the average account balance is more than $1,200.

7. 处理 NULL¶
-
任何包含
NULL的代数表达式都返回NULL示例:5 + NULL 返回 NULL
- 任何包含
NULL的比较式都返回UNKNOWN
示例:5 < NULL 返回 UNKNOWN
- 在逻辑表达式中,
UNKNOWN遵循以下规则: - OR:
- (unknown or true) = true
- (unknown or false) = unknown
- (unknown or unknown) = unknown
- AND:
- (true and unknown) = unknown
- (false and unknown) = false
- (unknown and unknown) = unknown
- NOT:(not unknown) = unknown
- 在
WHERE谓词的运算结果中,UNKNOWN被视作False - 在
WHERE谓词中,若判断某项是否为NULL,应使用is null、is not null
示例:

- 任何包含
8. 总结¶
-
SELECT语句的通用格式 -
SELECT语句的执行顺序
四、嵌套子查询 Nested Subqueries¶
1. 派生关系 Derived Relations¶
- 派生关系(Derived Relations)的生存范围只局限于所处的 SQL 语句中
-
WITH谓词- 语法:
WITH local-view-name(attribute-name-1, ...) as ... - 用于定义局部视图(Local View)
示例:Find all branches where the total account deposit is greater than the average of the total account deposits at all branches.

- 不管是否被引用,导出表(或称嵌套表)必须给出别名
- 语法:
2. 常用关键词¶
in、not in-
some、all-
some的定义:
-
all的定义:
-
-
exists、not exists- 用于测试关系是否非空

-
unique、not unique- 用于测试符合条件的元组是否有多个
示例:Find the student names who have enrolled more than 10 courses.
实现 1:(关键词
in、not in)
实现 2:(为导出表给出别名
TT)

示例:Find all customers who have both an account and a loan at the Perryridge branch.
实现 1:(关键词
in、not in)
实现 2:(注意表
t的生存周期)

示例:Find all branches that have greater assets than some branch located in Brooklyn.
正例:(自我比较)
反例:(没有为导出表指定别名,从而造成混淆)

示例:Find the names of all branches that have greater assets than all branches located in Brooklyn.
实现:(
all关键词)

示例:Find all customers who have at least two accounts at the Perryridge branch.
实现:(
unique关键词)




五、对数据库的修改¶
1. 删除记录¶
- 格式:
DELETE FROM table/view-name WHERE condition - 每次只能删除一张表内的记录
- 对于嵌套的指令,内层指令完成后才开始执行外层指令(见下方示例 2)
示例:
DELETE FROM account WHERE branch_name in (SELECT branch_name FROM branch WHERE branch_city = ‘Needham’)示例:
问题:这样删除,是否会导致 balance 的平均值在删除过程中发生变化,从而导致错误?
答:不会,SQL 先计算
avg(balance)并找到所有待删的记录后,再统一执行删除

2. 插入记录¶
-
格式 1:由给定值插入记录
-
格式 2:由查询结果插入记录
示例:

示例:
3. 更新记录¶
-
一般的记录更新
示例:当有多条更新语句时,注意更新语句的顺序,避免相互影响

- 使用
case语句的记录更新 - 语法:
when <condition> then <do sth...> else <do sth...>
示例:Increase all accounts with balances over $10,000 by 6%, and all other accounts receive 5%.

- 使用视图进行更新
- 建立在单个基本表上的视图,且视图的列对应表的列,称为行列视图
- 只有行列视图可以用于更新数据
- 使用
4. 事务 Transactions¶
- 概念:事务是作为单个逻辑单元执行的一系列查询和数据更新语句
- 事务的特性:原子性(atomicity)、一致性(consistence)、隔离性(isolation)、持久性(durability)
- 事务终止的条件
- COMMIT WORK:使事务的所有更新在数据库中永久存在
- ROLLBACK WORK:撤消事务执行的所有更新(如果事务的任何步骤失败,则事务已完成的所有工作都可以通过 ROLLBACK WORK 撤消。)